This paper presents a history of deep learning from Aristotle to the present time. The different milestones are summarized in this table:
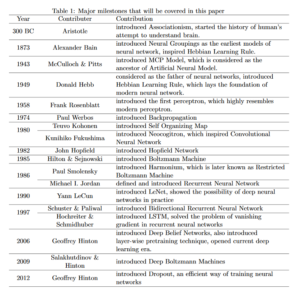
So it is clear that many ideas date to several decades ago. In the article, the authors conclude:
This paper could serve two goals: 1) First, it documents the major milestones in the science history that have impacted the current development of deep learning. These milestones are not limited to the development in computer science fields. 2) More importantly, by revisiting the evolutionary path of the major milestone, this paper should be able to suggest the readers that how these remarkable works are developed among thousands of other contemporaneous publications. Here we briefly summarize three directions that many of these milestones pursue:
- Occam’s razor: While it seems that part of the society tends to favor more complex models by layering up one architecture onto another and hoping backpropagation can find the optimal parameters, history says that masterminds tend to think simple: Dropout is widely recognized not only because of its performance, but more because of its simplicity in implementation and intuitive (tentative) reasoning. From Hopfield Network to Restricted Boltzmann Machine, models are simplified along the iterations until when RBM is ready to be piled-u
- Be ambitious: If a model is proposed with substantially more parameters than contemporaneous ones, it must solve a problem that no others can solve nicely to be remarkable. LSTM is much more complex than traditional RNN, but it bypasses the vanishing gradient problem nicely. Deep Belief Network is famous not due to the fact the they are the first one to come up with the idea of putting one RBM onto another, but due to that they come up an algorithm that allow deep architectures to be trained effectively.
- Widely read: Many models are inspired by domain knowledge outside of machine learning or statistics field. Human visual cortex has greatly inspired the development of convolutional neural networks. Even the recent popular Residual Networks can find corresponding mechanism in human visual cortex. Generative Adversarial Network can also find some connection with game theory, which was developed fifty years ago.
Coming from the field of economics and game theory, we cannot agree more especially when we read the literature of reinforcement learning (RL) or generative adversarial network. Once we talk about strategic agents with objectives and payoffs to maximize it is very similar to economics. There are differences between economics and machine learning in the approach of solving these problems and we will discuss some research that studies them.

