
What are Generative Adversarial Networks
Generative Adversarial Networks or GANs (Goodfellow et al., 2014) are a machine learning technique that produces very realistic-looking objects in images, videos, or texts. For instance, Figure 1 shows faces of people who do not exist. These faces are extremely realistic and borrow features from real people. It is more sophisticated than just taking the eyes of Jill, the forehead of Jane, and the mouth of Jaclyn. The whole face composition is very coherent.




Figure 1. Photos from https://www.thispersondoesnotexist.com/
Other applications include creating handwriting, painting of a given style, photos from sketches, cartoon characters, blending images, image correction, image synthesis, medical images, 3D images, image super-resolution, audio synthesis, music generation, data generation, videos from still images, environments in games, etc. It is a very powerful tool to create realistic sample data when the data is expensive or difficult to collect such as medical images or to generate manually.
GANs are also used to produce fake photos and videos. In Figure 2 for instance, the actor Jordan Peele makes President Obama say sentences that he never said before. His facial movements were transferred to president Obama’s face using GANs. The same technology is used to include actors who have passed away in new films or replace an actor with another one (the princess Leia played by Carrie Fisher in Star Wars).

Figure 2. Fake video of President Obama. Source: https://youtu.be/cQ54GDm1eL0
How do GANs work
GANs have their origins in generative models such as autoencoders and variational autoencoders. The idea is to have latent fundamental variables of lower dimension drive the features of the object the GANs want to model. Then by varying these lower-dimensional variables, deterministically or randomly, a neural network can produce new objects that are different from the original ones but that remind faithful to the class of objects. New images of human faces can be generated from the same latent variables that created the existing human faces but they cannot be generated from images of animals or buildings.
Generator and Discriminator
A model that generates new objects is called a Generator. The main question the Generator has to answer is: How does it know that the new objects are realistic enough? If it was an autoencoder, a particular neural network often used for dimensionality reduction, it would be trained to generate the same object after passing through a network with a limited number of features, the encoder. A decoder will then reconstruct an object from the latent features. With a variational autoencoder, the latent variables are stochastic.
Figure 3. Autoencoder
GANs work differently though:
- The Generator starts with the random values and produces new objects, say new images.
- It then feeds into a second model, the Discriminator, which tells the Generator if the image it produces is either real or fake with some probability.
- The feedback is given by the Discriminator and informs the Generator about where it should improve.
- The Discriminator is a classifier that is trained with a mix of real images (labeled as true) and images from the Generator (labeled as false or fake).
Figure 4. Generative Adversarial Networks with a generator and a discriminator
GAN objective function
The generator and discriminators are trained to minimize a binary cross-entropy loss function. For each observation, the true label is compared to the probability of being true by taking the product of the true label (1 for true, 0 for false) and the logarithm of the probability of being true. We take the negative of this product because we want to minimize the loss. We then add all these products across all the observations in a given batch.
Figure 5. Loss function for one single observation
In figure 5, we show the cross-entropy loss for one single observation. If the label is true, we are on the decreasing green curve, and minimizing the loss means the probability of being true should move towards 1. The model has to adjust its weights so that future outputs are more likely to be true. If the label is false then the probability should get closer to 0.
The cross-entropy loss for the generator uses the probabilities given by the discriminator and the true labels as 1 since the generator wants to fool the discriminator into thinking that its images are genuine. The generator never gets to see the true training data.
The cross-entropy loss for the discriminator uses the probabilities given by the discriminator and the true labels, 1 if the observations come from the real training data and 0 if the data come from the generator.
GAN training
The generator and the discriminator take turns to train and improve their performance as they receive more feedback. Their skill levels (for the generator to produce realistic images, for the discriminator to tell genuine and fake images apart) have to progress together so that both the generator and the discriminator continue improving.
The training consists of the generator producing a batch of images and receiving feedback from the discriminator. A generator loss is then calculated, using gradient descent, the weights of the generator can be adjusted to minimize the loss. The discriminator is also trained with a mix of training data and fake data from the generator. Its weights are also adjusted to better discriminate between the genuine and fake images.
Different GANs
Since 2014, there have been many models of GAN. GANs tend to be application-specific. We review some of the most popular so far.
Deep Convolutional GAN (DCGAN)

Figure 6. Bedrooms generated by DCGAN. Source: Radford et al., 2016
A big step was made with deep convolutional generative adversarial networks (DCGANs), introduced in (Radford et al., 2016). The authors use an improved GAN architecture compared to the original GAN paper. They use deconvolutions instead of pooling layers, batch normalization, remove fully connected layers, use ReLU, Tanh in the generator, and LeakyReLU in the discriminator.
Their model is used for unsupervised representation learning and can learn a hierarchy of representation. They can generate convincing images of scenes such as bedrooms (Figure 6) and use their model for representation learning. They can for instance look for part of the layers that identify windows and remove them. Their model can perform some basic feature arithmetic such as:
smiling woman – neutral woman + neutral man = smiling man (Figure 7).

Figure 7. Some arithmetic of feature representation. Source: Radford et al., 2016
Conditional GAN
Figure 8. Conditional Generative Adversarial Nets
Conditional Generative Adversarial Nets (CGANs) were introduced (Mirza and Osindero, 2014). With CGANs, the conditioning value such as a class is used by both the generator and discriminator as an additional input layer. In Figure 8, it is a class y. The model can generate specific images based on class labels. The model is trained on MNIST images conditioned on their class labels (0 to 9) and can generate realistic handwritten digits (Figure 9).

Figure 9. Digits generated by the CGAN model. Source: Mirza and Osindero, 2014
The model can also be used for image tagging and produce image description. It is combined with a convolutional model and a text model to predict description tags from the image features. The model is trained on Flickr images with tags and annotation created by the users.
Style GAN
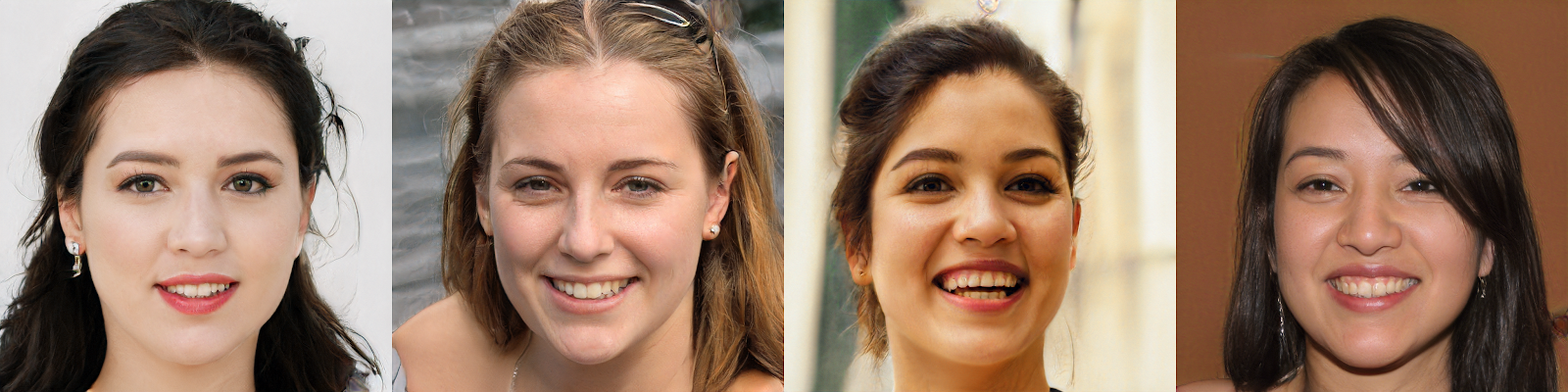
Figure 10. Style GAN sample photos
The Style-Based Generator Architecture for Generative Adversarial Networks or Style GAN was created by a team at Nvidia (Karras et al., 2019). The model has a different generator architecture with a mapping network that maps inputs to latent variables and a synthesis network that transforms the latent variables, combines them with random noises, and then maps them to different layers of a neural network. The quality of the images is much improved thanks to this more advanced architecture (Figure 10). Its flexibility allows a better separation of high-level attributes and stochastic variation of images. The latent variables can be adjusted to control the image features.
Cycle GAN

Figure 11. Cycle GAN example: a horse with zebra stripes
Cycle-Consistent Adversarial Networks (Cycle GANs) (Zhu et al., 2020) introduced new image translation methods. Image translation maps an image to a new image of a different style. In Figure 11, a horse becomes a zebra. A painting by Monet can be made as a painting with the style of Van Gogh or a photo can be made as a painting by different artists (Figure 12).

Figure 12. A photo is translated into a painting by different artists. Source Zhu et al., 2020.
Cycle GAN does not use pairs of data to train in a supervised learning fashion. It generates the new images from Monet (M) paintings with a generator and a discriminator gives the probability that the images look like they are from Van Gogh (V). It performs the task in reverse, starting from Van Gogh paintings and makes them into Monet paintings. It is using these two GAN losses. Besides, it verifies that if a Monet painting is translated into a Van Gogh painting and translated back, it remains very close to the original. This is the forward cycle consistency. Therefore the Cycle GAN loss is:
Cycle GAN Loss = GAN Loss (M to V) + GAN Loss (V to M) +Consistency Loss (M – V – M)
Cycle GAN is a very powerful tool to perform style transfer of all sorts, it can change one animal species to another, one set of fruits to another (apples to oranges), one season to another (summer to winter) in a photo, etc.
References
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y., 2014. Generative Adversarial Nets, in: Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q. (Eds.), Advances in Neural Information Processing Systems 27. Curran Associates, Inc., pp. 2672–2680.
Karras, T., Laine, S., Aila, T., 2019. A Style-Based Generator Architecture for Generative Adversarial Networks. ArXiv181204948 Cs Stat.
Mirza, M., Osindero, S., 2014. Conditional Generative Adversarial Nets. ArXiv14111784 Cs Stat.
Radford, A., Metz, L., Chintala, S., 2016. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ArXiv151106434 Cs.
Zhu, J.-Y., Park, T., Isola, P., Efros, A.A., 2020. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. ArXiv170310593 Cs.